· Antonio Nocerino · AI & Machine Learning, Software Development, Technologies & Tools · 22 min read
"Attention Is All You Need": Revolutionizing AI with the Transformer Architecture
This article examines the "Attention Is All You Need" paper, highlighting how the Transformer architecture, via attention and parallel processing, revolutionized NLP and became the basis for LLMs
![Transformer Architecture Overview]
📋 Table of Contents
- 🤖 What is the Transformer Architecture?
- 🌟 Why Transformers Matter in AI
- ❌ Problems with Previous AI Models
- ✅ How Transformers Solve These Problems
- 🔧 Understanding the Transformer Components
- 🎯 The Attention Mechanism Explained
- 🎭 Multi-Head Attention
- 🏗️ Encoder-Decoder Architecture
- 🌍 Real-World Applications
- ⚠️ Current Limitations
- 🔮 Future of Transformer Technology
🤖 What is the Transformer Architecture?
The Transformer architecture is a revolutionary deep learning model introduced by Google researchers in their groundbreaking 2017 paper “Attention Is All You Need.” This architecture fundamentally changed how artificial intelligence processes and understands human language.
Think of the Transformer as a highly sophisticated reading comprehension system. Unlike traditional models that read text word by word (like following your finger across a page), Transformers can examine entire paragraphs simultaneously, understanding complex relationships between words regardless of how far apart they appear in the text.
 Visualization showing how attention connects related words across a sentence
Visualization showing how attention connects related words across a sentence
🔑 Key Features of Transformers
Let me walk you through the three fundamental characteristics that make Transformers so powerful:
⚡ Parallel Processing: Instead of reading text sequentially like older models, Transformers process all words in a sentence simultaneously. This is like the difference between reading a book one letter at a time versus instantly comprehending entire pages.
🎯 Self-Attention Mechanism: This is the core innovation that allows every word to “attend to” or consider every other word in the context. Imagine each word having the ability to simultaneously examine and learn from every other word in the sentence.
📈 Scalability: The architecture scales beautifully from small experimental models to massive systems with billions of parameters. This scalability enabled the creation of modern Large Language Models like GPT-4 and BERT that we interact with daily.
🌟 Why Transformers Matter in AI
The Transformer architecture represents one of the most significant leaps forward in artificial intelligence history. Its impact extends far beyond academic research into practical applications that affect millions of people daily.
🏗️ The Foundation of Modern AI
Every major language model you interact with today builds upon Transformer principles. Let me show you how pervasive this influence has become:
- 🤖 ChatGPT and GPT Models: Built entirely on Transformer architecture
- 🔍 Google’s Bard: Uses Transformer-based language understanding
- 💻 Microsoft Copilot: Leverages Transformers for code generation and assistance
- 🔤 BERT and Similar Models: Apply Transformer principles for text understanding
The Transformer didn’t just improve existing capabilities—it unlocked entirely new possibilities that seemed like science fiction just a few years ago.
📊 Revolutionary Performance Improvements
When the original Transformer paper was published, it immediately achieved remarkable results that demonstrated its potential:
🎯 Translation Accuracy: Achieved state-of-the-art results on machine translation tasks, producing more natural and contextually appropriate translations than previous methods.
⚡ Training Speed: Reduced training times from weeks to days, making advanced AI research more accessible and practical.
🖥️ Hardware Efficiency: Enabled full utilization of modern GPU hardware through parallel processing, unlocking computational power that sequential models couldn’t access.
📚 Scalability: Provided a clear path for building increasingly sophisticated systems by scaling up model size and training data.
❌ Problems with Previous AI Models
To truly appreciate the Transformer’s innovation, we need to understand the fundamental problems it solved. Before Transformers dominated the field, Natural Language Processing relied heavily on Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs).
 Comparison showing sequential RNN processing versus parallel Transformer processing
Comparison showing sequential RNN processing versus parallel Transformer processing
🐌 The Sequential Processing Bottleneck
Imagine trying to understand a complex novel while being forced to forget each chapter as you read the next one. This captures the fundamental challenge facing RNN-based models, which created several critical limitations:
📖 Word-by-Word Processing: RNNs examined text sequentially, processing one word at a time in strict order, like reading with a narrow spotlight that could only illuminate one word at a time.
⏳ Memory Fade: Information from earlier words would gradually fade as the model processed later words, similar to trying to remember the beginning of a very long sentence by the time you reach the end.
🔗 Lost Connections: Long-distance relationships between words became nearly impossible to maintain, making it difficult to understand complex grammatical structures or thematic connections.
😵 The Vanishing Gradient Problem
This technical challenge had profound practical implications for AI language understanding:
🌊 Information Degradation: As information traveled through the network from early words to later ones, it would gradually fade away, like a message being whispered through a long chain of people.
📏 Distance Limitations: By the time the model reached the end of a lengthy sentence, it had essentially forgotten what happened at the beginning, making coherent understanding impossible.
🔍 Example Impact: Consider this sentence: “The cat, which had been sleeping peacefully in the sunny garden all morning despite the neighbor’s dog barking loudly next door, suddenly jumped onto the fence.” An RNN would struggle to connect “cat” with “jumped” due to the long intervening clause.
💻 Computational Inefficiency
The sequential nature of RNNs created significant practical barriers:
⏸️ Processing Bottleneck: Each word had to wait for the previous word to be processed completely, creating a computational traffic jam that prevented efficient processing.
🖥️ Hardware Mismatch: Modern GPUs excel at parallel processing, but RNNs couldn’t utilize this computational power effectively, leading to underutilized hardware and longer training times.
💰 Cost Implications: The inability to process efficiently meant that training sophisticated models became prohibitively expensive and time-consuming, limiting research progress and practical applications.
✅ How Transformers Solve These Problems
The Transformer architecture addresses each of these fundamental problems through elegant engineering solutions that work together synergistically. Let me walk you through how each innovation contributes to the overall solution.
⚡ Parallel Processing Revolution
The shift from sequential to parallel processing represents one of the most significant architectural innovations in modern AI:
🔄 Simultaneous Analysis: Instead of processing words one at a time, Transformers examine all words in a sentence simultaneously, like being able to see and comprehend entire pages of text instantly.
🚀 Speed Improvements: This parallel approach immediately solved computational efficiency problems, with training times dropping dramatically and researchers finally able to build models that fully utilized modern hardware capabilities.
📈 Scalability Unlocked: The efficiency gains made it practical to train much larger models on much larger datasets, directly enabling the AI capabilities we see today.
🎯 The Attention Mechanism Solution
The attention mechanism represents the Transformer’s most innovative feature, solving the context and memory problems that plagued earlier architectures:
💡 Direct Connections: Rather than relying on information flowing sequentially through the network, attention allows every word to directly examine every other word in the context.
🔦 Smart Spotlight System: Think of attention as an intelligent spotlight system where each word can simultaneously illuminate and examine all other words in the sentence, identifying relevant relationships regardless of distance.
🔗 Relationship Preservation: When processing “jumped” in our earlier example, the attention mechanism can directly connect it to “cat” at the beginning, regardless of intervening words, solving the long-distance dependency problem.
🧠 Context Problem Resolution
By enabling direct connections between any two words in a sequence, Transformers solved multiple context-related challenges:
📝 Grammatical Relationships: Complex grammatical structures like subject-verb agreement across long sentences became accessible to the model.
💭 Semantic Connections: The model could identify and utilize semantic relationships between words regardless of their positions in the text.
📖 Discourse Patterns: Long-range patterns like pronoun resolution and thematic coherence across entire documents became manageable for the first time.
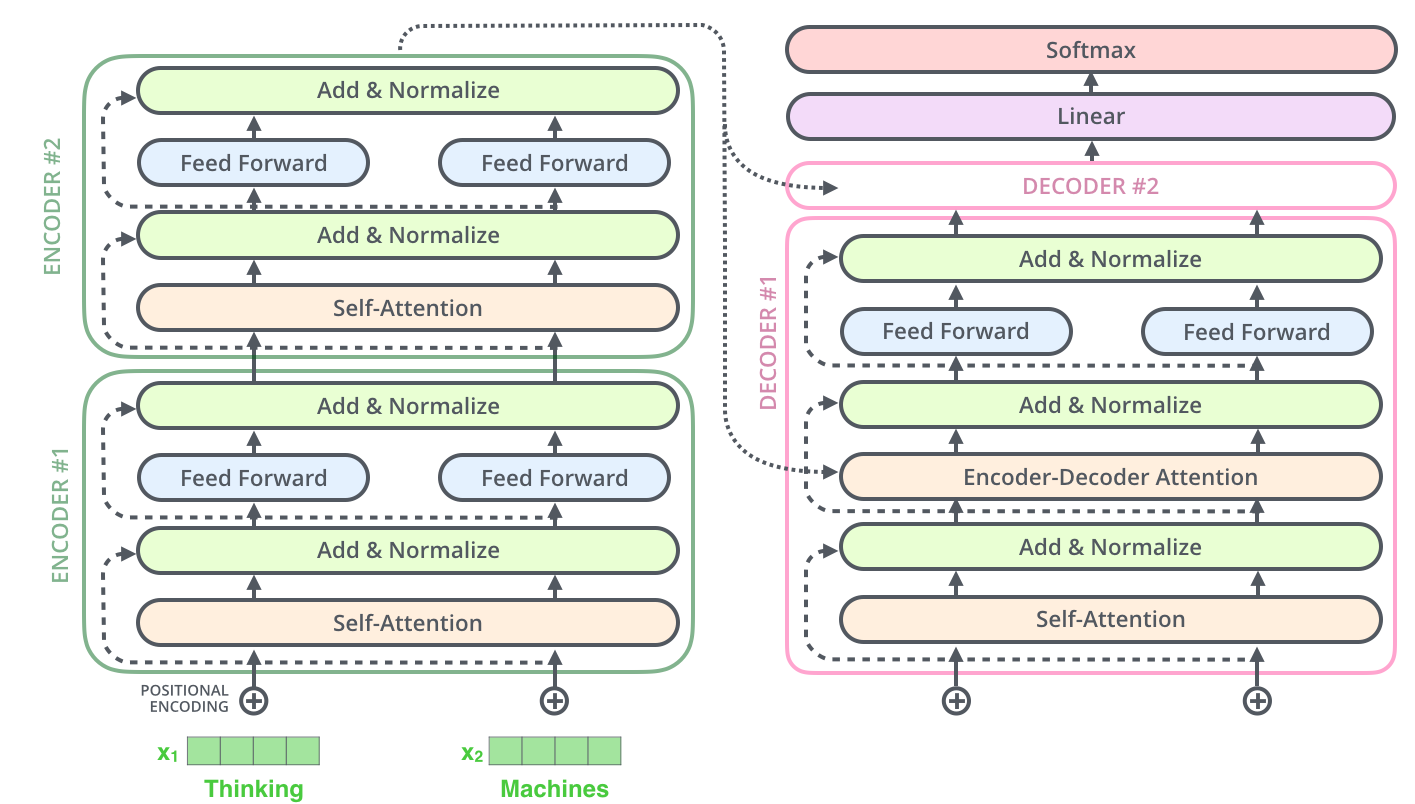
🔧 Understanding the Transformer Components
Let me guide you through the Transformer’s architecture step by step, building your understanding from the foundational components up to the complete system. This systematic approach will help you grasp how each piece contributes to the overall functionality.
 Complete Transformer architecture showing encoder and decoder stacks
Complete Transformer architecture showing encoder and decoder stacks
📝 Input Processing: Preparing Text for the Model
Before the Transformer can work its magic, text must be converted into a mathematical format the model can process. This happens through three crucial steps:
1. 🔤 Tokenization: Breaking Down Text
Think of tokenization as creating a vocabulary that the model can work with consistently:
✂️ Text Segmentation: The system breaks down text into smaller units called tokens, which might be whole words (“hello”), word fragments (“pre-”, “-ing”), or even individual characters depending on the approach.
📚 Vocabulary Creation: These tokens form a fixed vocabulary that the model uses throughout training and inference, ensuring consistent representation of language elements.
🎯 Strategic Choices: Different tokenization strategies affect model performance—word-level tokenization preserves meaning but creates large vocabularies, while character-level tokenization creates smaller vocabularies but loses semantic units.
2. 🧮 Embedding: Converting Words to Numbers
Embedding transforms discrete tokens into continuous mathematical representations:
🎨 Vector Creation: Each token gets converted into a high-dimensional numerical vector (typically 512 or 768 dimensions in practice).
📊 Semantic Mapping: These embeddings aren’t random—they’re learned representations that capture semantic meaning, where words with similar meanings develop similar vector representations.
🤝 Relationship Preservation: The embedding space preserves linguistic relationships, so “king” and “queen” would have similar embeddings (both are royalty), but “king” would also share certain mathematical relationships with “man” while “queen” shares relationships with “woman.”
3. 📍 Positional Encoding: Preserving Word Order
Since Transformers process all words simultaneously, they need a way to understand word order:
🎵 Mathematical Signatures: The original Transformer uses sine and cosine functions at different frequencies to create unique positional signatures for each position in the sequence.
🔢 Position Fingerprints: Each position receives a unique mathematical fingerprint that tells the model exactly where that word appears in the sentence.
➕ Addition Process: These positional encodings are added to the word embeddings, combining semantic meaning with positional information in a single representation.
🎯 The Attention Mechanism Explained
The self-attention mechanism represents the beating heart of the Transformer architecture. Understanding how attention works is crucial to grasping why Transformers are so powerful. Let me break down this sophisticated process into understandable components.
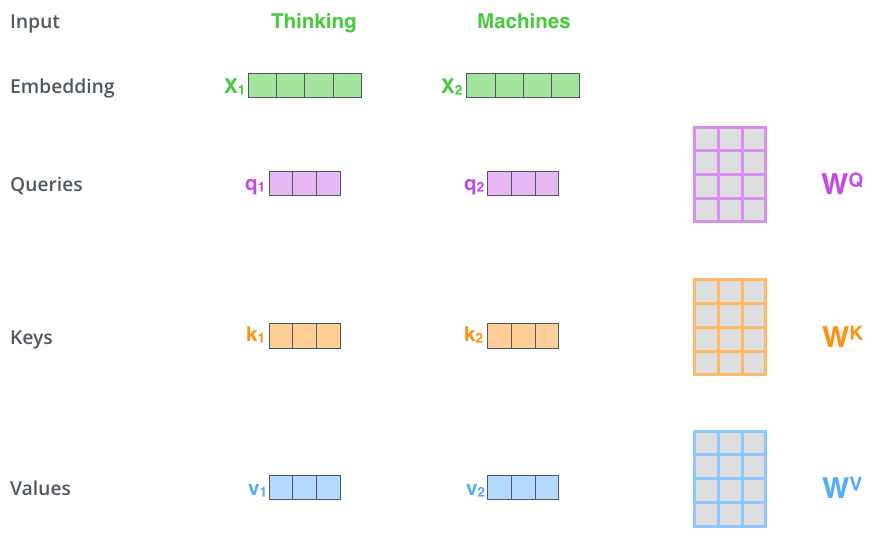 Visual breakdown of how self-attention creates Query, Key, and Value vectors
Visual breakdown of how self-attention creates Query, Key, and Value vectors
🔑 Query, Key, and Value: The Attention Trinity
For each word in the input, the attention mechanism creates three different vector representations that serve distinct purposes. Think of this like a sophisticated library system:
1. 🔍 Query Vectors: What Information Is Needed
Query vectors represent what information each word is seeking from other words in the context:
❓ Search Requests: Think of a Query as a detailed search request that mathematically describes what kind of information would be relevant and useful for understanding this particular word.
🎯 Contextual Needs: Different words need different types of context—a verb might query for its subject, while a pronoun might query for its referent.
📋 Mathematical Representation: The Query vector encodes these information needs in a high-dimensional space where similar needs have similar representations.
2. 🗝️ Key Vectors: What Information Is Available
Key vectors represent what information each word offers to other words:
📊 Information Catalog: Like entries in a database index, Keys advertise the type of information available in each word’s representation.
🏷️ Content Description: A Key describes what semantic, grammatical, or contextual information this word can provide to other words in the sequence.
🔗 Matching System: Keys are designed to match with relevant Queries through mathematical similarity, creating a sophisticated information retrieval system.
3. 💎 Value Vectors: The Actual Content
Value vectors contain the substantive information that gets shared when a word is deemed relevant:
📦 Information Payload: Once the Query-Key matching process determines relevance, Value vectors provide the actual content that gets incorporated into the final representation.
🎁 Rich Content: Values contain processed information about the word’s meaning, context, and relationships that can enhance other words’ understanding.
⚖️ Weighted Combination: Multiple Value vectors combine based on attention weights to create rich, contextually informed representations.
🧮 The Attention Calculation Process
The mathematical elegance of attention lies in its systematic approach to information combination:
Step 1: 📊 Score Calculation
🔢 Dot Product Operation: The model computes attention scores by taking the dot product of each word’s Query vector with every other word’s Key vector.
📈 Similarity Measurement: These scores represent how well each Query matches each Key—higher scores indicate greater relevance.
🌡️ Raw Attention Matrix: This creates a matrix where each cell represents how much attention one word should pay to another.
Step 2: 🎯 Score Normalization
📏 Scaling Factor: The raw scores are divided by the square root of the key dimension to prevent them from becoming too large.
🎲 Softmax Application: The scaled scores undergo softmax normalization, converting them into a probability distribution where all attention weights for each word sum to 1.0.
⚖️ Balanced Attention: This normalization ensures that each word’s attention is distributed appropriately across all other words.
Step 3: 🔄 Value Combination
✖️ Weighted Multiplication: The normalized attention weights multiply the corresponding Value vectors.
➕ Summation Process: These weighted Value vectors are summed to create the final attention output for each word.
🎨 Rich Representation: Each word’s final representation incorporates relevant information from every other word, weighted by computed relevance.
📐 Scaled Dot-Product Attention Formula
The complete attention mechanism follows this elegant mathematical formula:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
Let me explain each component of this formula:
QK^T: The dot product between Query and Key matrices, computing all pairwise attention scores simultaneously.
sqrt(d_k): The scaling factor (square root of the key dimension) that prevents numerical instability by keeping scores in a reasonable range.
softmax(): The normalization function that converts raw scores into well-behaved probability distributions.
V: The Value matrix that provides the actual content to be combined based on the computed attention weights.
🎭 Multi-Head Attention
Rather than using a single attention mechanism, Transformers employ multiple “attention heads” that operate in parallel, each learning to focus on different types of relationships between words. This parallel processing of different relationship types creates remarkably sophisticated language understanding.
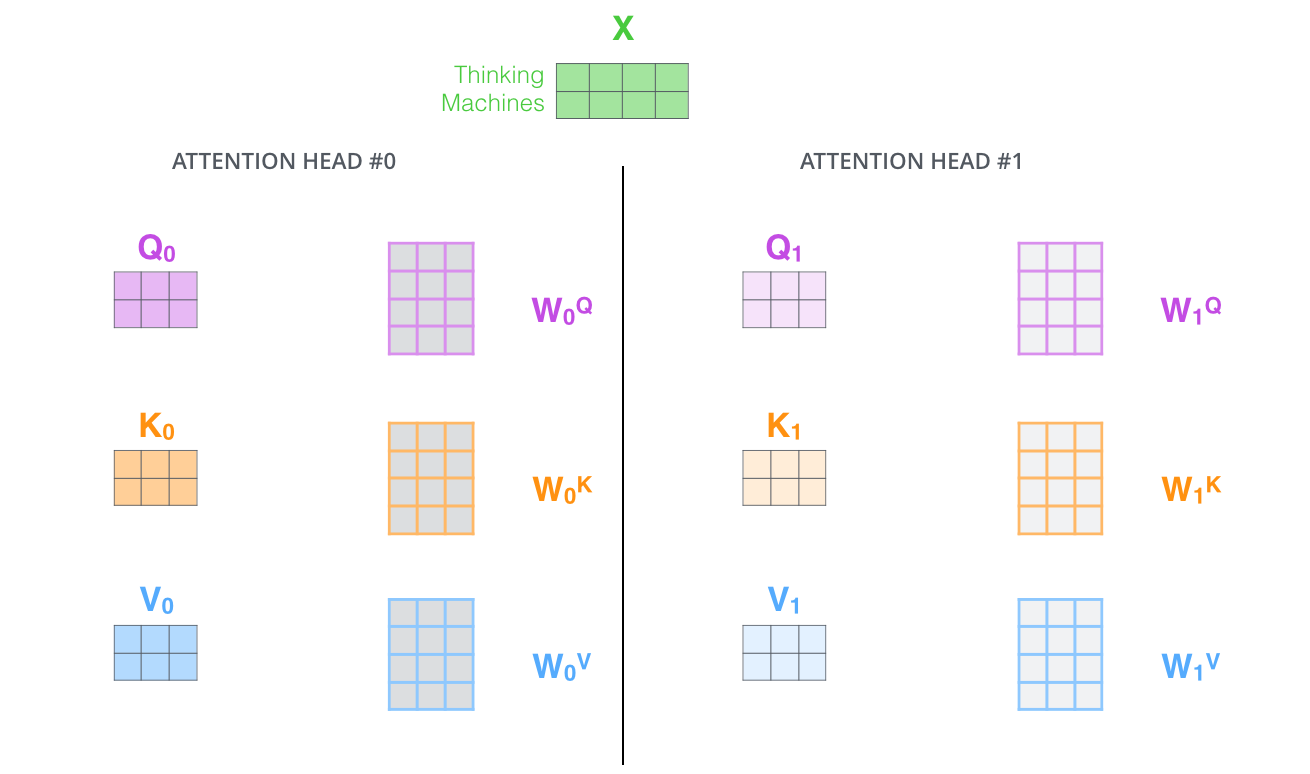 Multiple attention heads processing the same input to capture different relationship types
Multiple attention heads processing the same input to capture different relationship types
👥 Multiple Perspectives on the Same Text
Imagine having a team of expert linguists examine the same text simultaneously, with each expert specializing in different aspects of language understanding:
1. 📖 Grammar Specialist (Head 1)
🔗 Syntactic Relationships: One attention head might focus on grammatical relationships, tracking subject-verb agreement and syntactic dependencies.
🏗️ Sentence Structure: This head learns to identify phrases, clauses, and their hierarchical relationships within sentences.
📏 Dependency Parsing: It becomes expert at understanding how words depend on each other grammatically, like connecting adjectives to their nouns or verbs to their objects.
2. 💭 Meaning Specialist (Head 2)
🎨 Semantic Associations: Another head specializes in semantic relationships, identifying synonyms, antonyms, and conceptually related terms.
🌈 Conceptual Connections: This head learns to connect words that share thematic or conceptual relationships, even when they’re grammatically unrelated.
📚 Knowledge Integration: It becomes skilled at accessing and applying world knowledge encoded in the training data.
3. 📖 Story Specialist (Head 3)
🔄 Discourse Patterns: A third head might track discourse-level patterns, connecting pronouns to their referents and maintaining thematic coherence.
📈 Narrative Flow: This head learns to understand how information flows through a text, tracking topics and their development.
🎯 Reference Resolution: It becomes expert at resolving references like “it,” “they,” or “the company” to their appropriate antecedents.
🔧 The Multi-Head Process
The multi-head attention mechanism follows a systematic approach to combining these different perspectives:
1. 🎯 Parallel Processing
⚡ Simultaneous Operation: All attention heads process the input simultaneously, each using its own learned Query, Key, and Value transformations.
🎨 Specialized Learning: Each head develops its own expertise through training, learning to focus on different types of linguistic relationships.
📊 Independent Computation: The heads operate independently, allowing them to develop distinct specializations without interference.
2. 🔗 Output Combination
📎 Concatenation: After each attention head produces its own representation of the input, these multiple perspectives are concatenated together.
🎛️ Linear Transformation: The concatenated outputs pass through a learned linear transformation that integrates insights from all attention heads.
🎨 Unified Representation: This combination process creates final representations that incorporate grammatical, semantic, and discourse-level understanding simultaneously.
3. 📈 Benefits of Multiple Heads
🎯 Specialization: Different heads can focus on different aspects of language, creating more comprehensive understanding than any single attention mechanism could achieve.
🛡️ Redundancy: Multiple heads provide robustness—if one head fails to capture a particular relationship, others might succeed.
📊 Rich Representations: The combination of multiple perspectives creates representations that are far richer and more nuanced than single-head attention could produce.
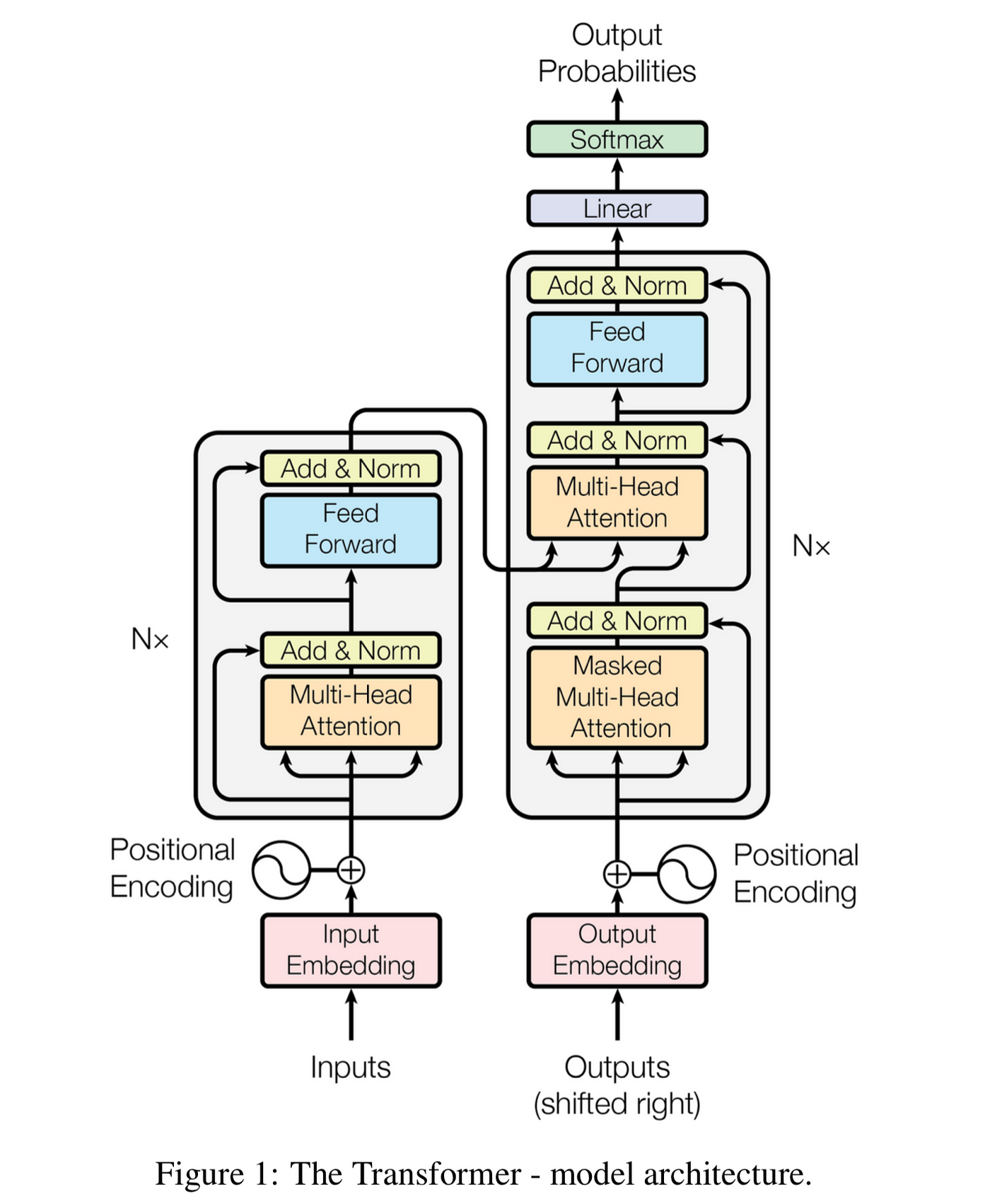
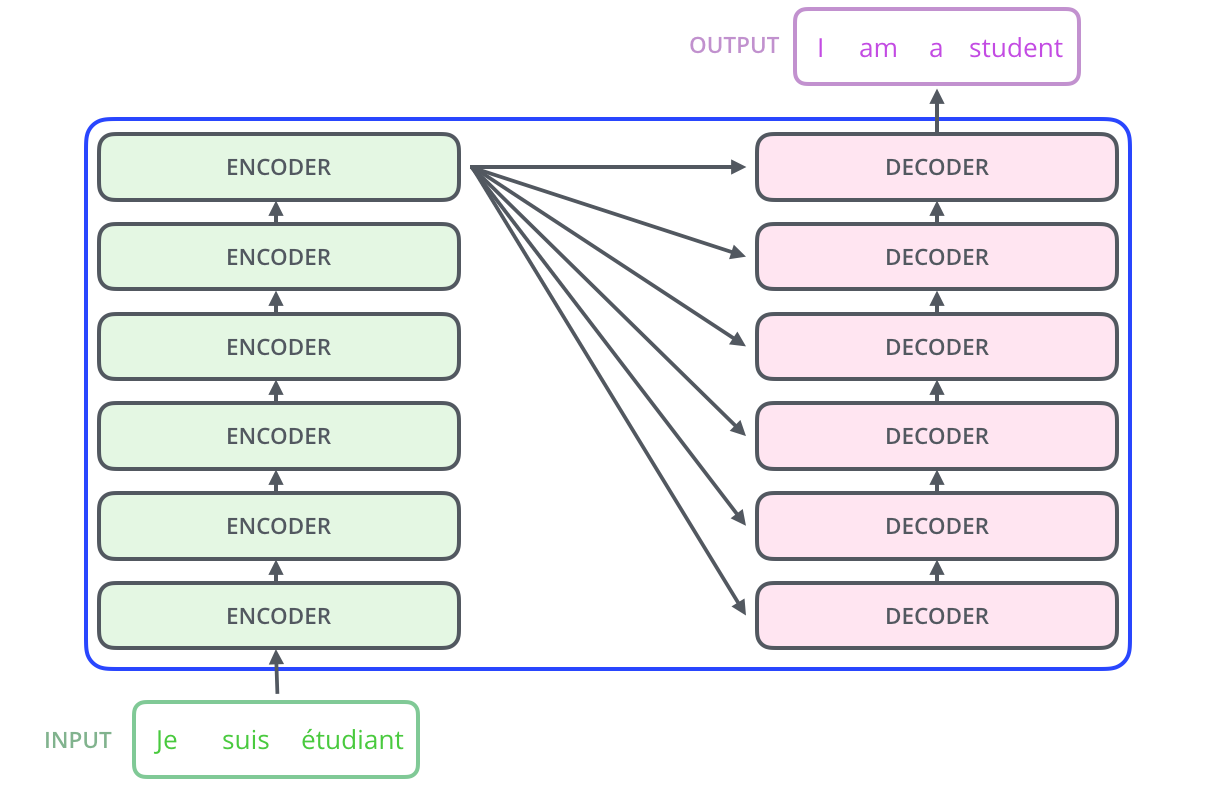
🏗️ Encoder-Decoder Architecture
The original Transformer uses a sophisticated encoder-decoder structure that divides language processing tasks into two complementary phases. This division of labor allows the model to handle complex sequence-to-sequence tasks like translation, summarization, and question answering with remarkable effectiveness.
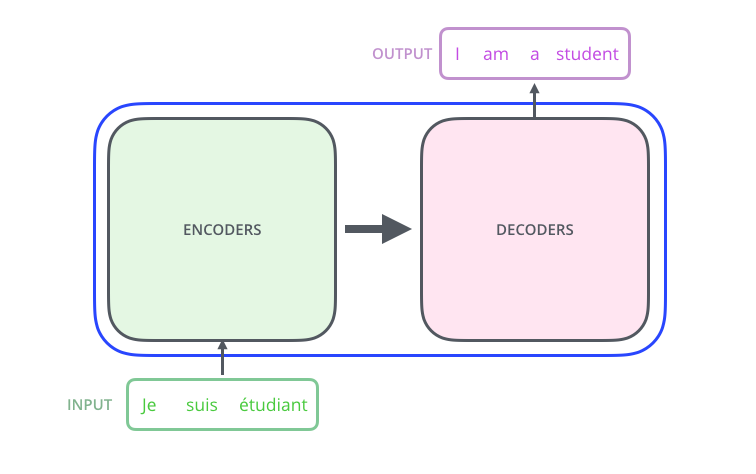 Encoder and decoder stacks working together for sequence-to-sequence tasks
Encoder and decoder stacks working together for sequence-to-sequence tasks
🔍 The Encoder: Deep Understanding of Input
The encoder’s primary responsibility involves processing the input sequence and creating rich, contextualized representations that capture all relevant information and relationships. Let me walk you through how this sophisticated understanding process works:
1. 📚 Layer-by-Layer Processing
🏗️ Stacked Architecture: Multiple encoder layers stack on top of each other (typically 6 layers in the original Transformer), with each layer building increasingly sophisticated representations.
🎯 Progressive Refinement: Early layers might focus on basic grammatical relationships and simple semantic connections, while deeper layers capture more abstract patterns and complex conceptual relationships.
🔄 Bidirectional Processing: The encoder operates bidirectionally, meaning each word can attend to every other word in the input sequence, enabling comprehensive context understanding.
2. 🧠 Internal Architecture
Each encoder layer contains two main components that work together:
👀 Multi-Head Self-Attention: This allows words to gather relevant information from all other words in the input, creating contextually rich representations.
🔧 Position-Wise Feedforward Network: These networks provide additional computational capacity, allowing the model to capture non-linear relationships that attention mechanisms alone might miss.
🔗 Residual Connections: Skip connections around each component help information flow smoothly through the deep network and prevent gradient vanishing problems.
3. 🎨 Output Characteristics
🌟 Rich Representations: Each word’s final encoder representation incorporates information from the entire input sequence, creating comprehensive understanding.
📊 Context Integration: The encoder outputs contain both local information (about individual words) and global information (about the entire sequence’s meaning and structure).
🎯 Task-Agnostic Understanding: These representations can be used for various downstream tasks, from classification to generation, making them highly versatile.
🎬 The Decoder: Strategic Output Generation
The decoder generates the output sequence one token at a time, using both the encoder’s rich representations and the tokens it has already generated. This autoregressive generation process ensures coherent, contextually appropriate outputs.
1. 🎯 Autoregressive Generation
⏳ Sequential Output: Unlike the encoder’s parallel processing, the decoder generates output tokens one at a time, building each new token based on all previously generated tokens.
🎪 Causal Attention: The decoder uses masked self-attention to prevent it from “cheating” by looking at future tokens during training, ensuring it learns to generate text based only on available information.
🔄 Iterative Process: Each generation step incorporates both the growing output sequence and the encoder’s understanding of the input, creating contextually appropriate continuations.
2. 🌉 Cross-Attention Integration
🔗 Encoder-Decoder Connection: Cross-attention layers in the decoder allow it to selectively attend to relevant parts of the encoder’s output while generating each new token.
🎯 Selective Focus: Different parts of the output might need to focus on different parts of the input—translation systems, for example, might attend to different source words when generating different target words.
📊 Dynamic Attention: The attention patterns change dynamically as generation progresses, allowing the decoder to maintain coherent relationships with the input throughout the generation process.
3. 🎨 Layer Structure
Each decoder layer contains three main components:
🎭 Masked Self-Attention: Allows each position to attend to all earlier positions in the output sequence, building coherent continuations.
🌉 Cross-Attention: Enables the decoder to incorporate relevant information from the encoder’s understanding of the input.
🔧 Feedforward Network: Provides additional processing power for capturing complex patterns in the generation process.
🎛️ Working Together: The Complete System
📖 Input Processing: The encoder creates a comprehensive understanding of the input sequence, capturing all relevant relationships and context.
🎬 Output Generation: The decoder uses this understanding to generate appropriate outputs, maintaining coherence both with the input and within the generated sequence.
🔄 Feedback Loop: The decoder’s attention to the encoder creates a feedback loop where generation decisions are informed by deep understanding of the input context.
🌍 Real-World Applications
Transformers have revolutionized numerous fields beyond their original machine translation application, demonstrating remarkable versatility and adaptability across diverse domains. Let me show you how this architectural innovation has transformed various industries and research areas.
📝 Natural Language Processing Applications
The impact of Transformers on language-related tasks has been nothing short of revolutionary:
1. 🗣️ Machine Translation
🌐 Global Communication: Google Translate’s dramatic quality improvements in recent years stem largely from Transformer adoption, enabling more natural and contextually appropriate translations.
📚 Nuanced Understanding: Transformers capture cultural context, idiomatic expressions, and subtle linguistic nuances that previous systems missed.
⚡ Real-Time Processing: The parallel processing capabilities enable fast, high-quality translation for live communication and large-scale document processing.
2. ✍️ Text Generation and Writing Assistance
🎨 Creative Writing: From poetry to storytelling, Transformers can generate creative content that often appears indistinguishable from human writing.
📄 Content Creation: Automated article writing, marketing copy generation, and technical documentation creation have become practical realities.
🔧 Writing Enhancement: Tools like Grammarly and writing assistants use Transformer-based models to improve clarity, style, and coherence.
3. ❓ Question Answering Systems
🧠 Reading Comprehension: Modern systems can understand and respond to complex queries about diverse topics, demonstrating genuine comprehension rather than simple keyword matching.
🔍 Information Retrieval: Search engines now use Transformers to better understand user intent and provide more relevant, contextual results.
🤖 Conversational AI: Chatbots and virtual assistants leverage Transformer architectures to maintain coherent, helpful conversations across extended interactions.
4. 📊 Text Summarization
📰 News Summarization: Automatic generation of concise news briefs from lengthy articles, helping readers stay informed efficiently.
📚 Document Processing: Legal document analysis, research paper summarization, and corporate report condensation have become automated processes.
🎯 Extractive and Abstractive: Transformers excel at both extracting key sentences and generating novel summaries that capture essential information.
🎨 Beyond Language: Universal Applications
The attention mechanism’s power extends far beyond text processing:
1. 👁️ Computer Vision Revolution
🖼️ Vision Transformers (ViTs): These models apply attention mechanisms to image patches rather than words, achieving remarkable results in image recognition and classification.
🎯 Object Detection: Transformer-based systems can identify and locate multiple objects within complex scenes with unprecedented accuracy.
🎨 Image Generation: Modern image generation systems like DALL-E use Transformer architectures to create photorealistic images from text descriptions.
2. 🔬 Scientific Applications
The versatility of attention mechanisms has enabled breakthroughs across scientific domains:
🧬 Protein Folding: DeepMind’s AlphaFold uses attention mechanisms to predict protein structures, revolutionizing biological research and drug discovery.
🧪 Drug Discovery: Pharmaceutical companies use Transformer-based models to identify promising drug candidates and predict molecular properties.
🔬 DNA Analysis: Genomic research benefits from Transformers’ ability to identify patterns and relationships in long DNA sequences.
3. 🎵 Multimodal Learning
🎬 Video Understanding: Systems that analyze video content by combining visual, audio, and textual information using Transformer architectures.
🎨 Creative AI: Models that generate content across multiple modalities, like creating images from text descriptions or generating music from emotional descriptions.
🤖 Robotics: Robots that understand and respond to natural language commands while processing visual and sensor data simultaneously.
💼 Industry Transformations
Let me show you how different industries have been transformed by Transformer applications:
1. 🏥 Healthcare
📋 Medical Documentation: Automated transcription and analysis of medical records, reducing administrative burden on healthcare providers.
💊 Clinical Decision Support: AI systems that assist doctors by analyzing patient data and medical literature to suggest diagnoses and treatments.
🔬 Research Acceleration: Faster analysis of medical literature and research papers to identify promising treatments and drug interactions.
2. 💰 Finance
📊 Risk Assessment: Automated analysis of financial documents, news, and market data to assess investment risks and opportunities.
🤖 Customer Service: Intelligent chatbots that can handle complex financial queries and provide personalized advice.
📈 Market Analysis: Real-time processing of financial news and social media sentiment to inform trading decisions.
3. 🎓 Education
👨🏫 Personalized Learning: AI tutors that adapt to individual learning styles and provide customized educational content.
📝 Automated Grading: Systems that can evaluate written assignments and provide detailed feedback on content, structure, and style.
🌐 Language Learning: Applications that provide conversational practice and personalized language instruction.
⚠️ Current Limitations
Understanding Transformer limitations helps set realistic expectations and guides ongoing research directions. While these models have achieved remarkable capabilities, they still face several fundamental challenges that researchers actively work to address.
🤖 Fundamental Challenges
1. 👻 Hallucinations: The Confidence Problem
This represents one of the most significant concerns in practical Transformer applications:
🎭 Confident Inaccuracy: Transformer models can generate confident-sounding but factually incorrect information, presenting false information with the same certainty as accurate facts.
🧠 Pattern Completion vs. Knowledge: These models are fundamentally probability-based text generators rather than knowledge databases, creating text based on statistical patterns rather than verified information.
⚠️ Practical Implications: In high-stakes applications like healthcare, legal advice, or financial planning, hallucinations can have serious consequences, requiring careful human oversight and verification.
2. 🧮 Reasoning Limitations
Current Transformers struggle with tasks requiring systematic logical thinking:
🔢 Mathematical Reasoning: While they can perform basic arithmetic, complex multi-step calculations and mathematical proofs remain challenging.
🧩 Logical Puzzles: Tasks requiring systematic deduction, like solving logic puzzles or following complex if-then chains, often exceed their capabilities.
🔄 Function Composition: Breaking down complex problems into sequential steps and applying multiple operations systematically proves difficult.
🎯 Pattern vs. Reasoning: Current evidence suggests that Large Language Models perform sophisticated pattern completion rather than true symbolic reasoning, limiting their problem-solving approaches.
3. 💻 Computational Demands
The power of large Transformer models comes with significant practical costs:
⚡ Energy Consumption: Training state-of-the-art models requires enormous amounts of electricity, raising environmental and cost concerns.
🖥️ Hardware Requirements: The computational resources needed for training and running large models remain accessible primarily to major technology companies and well-funded research institutions.
💰 Economic Barriers: The high costs create barriers to entry for smaller organizations and researchers, potentially limiting innovation and competition.
🏗️ Architectural Constraints
Several fundamental limitations stem from the Transformer architecture itself:
1. 📏 Context Length Limitations
📊 Quadratic Scaling: The attention mechanism’s computational complexity scales quadratically with sequence length, making very long documents prohibitively expensive to process.
🧠 Memory Constraints: Current models can typically handle contexts of thousands rather than millions of words, limiting their ability to process entire books or large datasets.
⚖️ Quality vs. Length Trade-offs: Extending context length often requires reducing model quality or increasing computational costs dramatically.
2. 📚 Training Data Dependencies
🎯 Quality Limitations: Model capabilities are fundamentally constrained by the quality, diversity, and accuracy of training data.
📅 Temporal Bias: Models reflect the time period of their training data, potentially missing recent developments or changes in knowledge.
🌍 Cultural and Linguistic Bias: Training data biases directly affect model behavior, potentially reinforcing societal biases or underrepresenting certain perspectives.
3. 🔄 Adaptation Challenges
🏫 Learning New Information: Models struggle to continuously learn and integrate new nformation without extensive retraining (which is costly and time-consuming).
🔧 Fine-tuning Complexity: Adapting pre-trained models to specific tasks or domains equires careful fine-tuning, which can be a complex and resource-intensive process.
🚫 Catastrophic Forgetting: When fine-tuned on new data, models can sometimes “forget” previously learned information, making incremental updates challenging.